
IOT, AI, Machine Learning and…Statistics?
Good old fashioned math, y’all
By Kevin Kelly, Co-founder, Head of Software, Agrology
It’s easy to get excited about the state of applied Machine Learning (ML) and artificial intelligence (AI) today. The power of frameworks like Keras/Tensorflow and PyTorch, built on the ubiquitous and approachable language Python, have empowered engineers who have the will (and some Google Fu) to create things that were impossible just a few years ago.
With the formation of Agrology, Adam, Tyler and I set out to build a predictive agriculture platform for farmers. A platform that combines datastreams from our proprietary and off-the-shelf sensors, with regional weather forecasts, and then synthesizes the data and predicts outcomes several days out. These predictions help farmers stay one step ahead of the ever-growing threats posed by climate change. We understood machine learning could bring a sea change in the way farmers understand what is happening, both below and above the soil and, crucially, keep them ahead of problems.
Agrology’s whole business model is rooted in ML. For a given price point we can deploy 10x more sense nodes, each with 10x more sensors, generating two orders of magnitude more data to train our models on. The models take multiple input datastreams, over multiple seasons, and accurately forecast disparate metrics days into the future. We provide actionable insights from these models, because without actionable plans 100x more data is 0x more useful to farmers.
So where do statistical models fit in? You might be thinking, “Statistics reminds me of Excel macros, and ‘macro’ is not a VC buzzword.” I think it’s only fitting to put the answer in a nice spreadsheet for you:
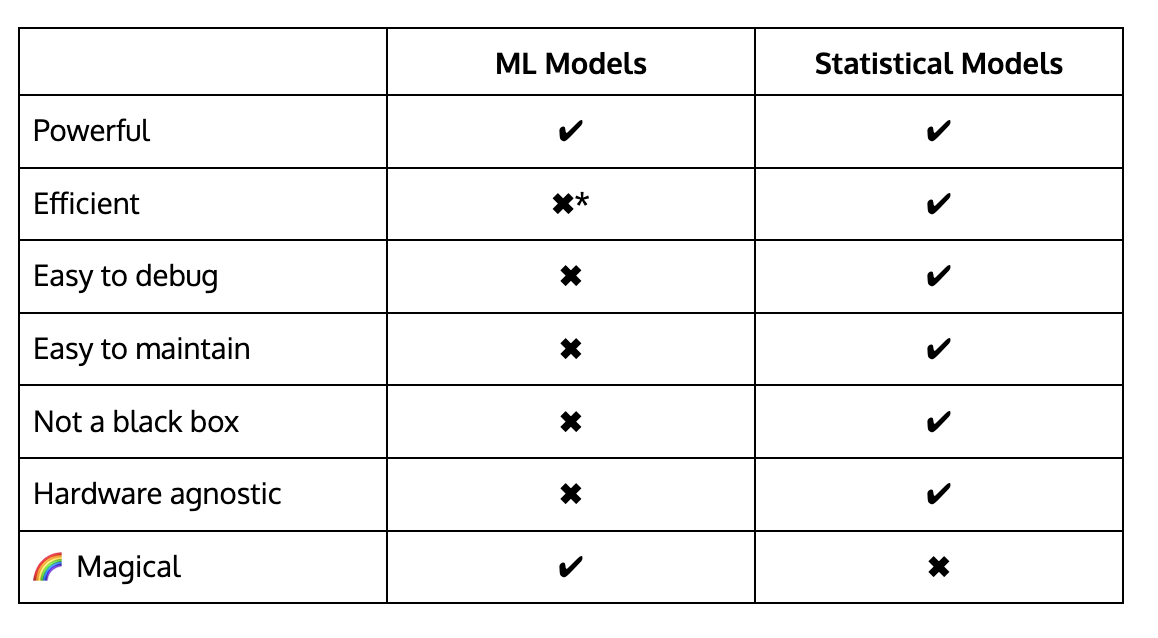
Table 1. ML vs Statistical Models. *Relative to statistical models
Since I began researching how to build a Machine Learning model pipeline that fits Agrology’s needs, I noticed responses to other peoples’ Stack Overflow questions frequently include “Do you really need ML for this?” Oftentimes the answer is no, as presented ML can be overcomplicated for a problem. Not every problem is an ML problem.
When I started building the Agrology microclimate forecast model, we had just wrapped deployment of our very first ML synthetic sensor forecasting models. I was very proud of not only the performance of the models, but the extensibility of the architecture. By changing a few input features, the same architecture could train all of our forecasting models. So, naturally when I approached the microclimate forecast problem, I saw it as just another nail to my ML hammer.
Pretty quickly, however, those Stack Overflow comments started to become relevant again and I started looking at non-ML solutions. I built a statistical model that defined the mean and standard deviation of the real historical data for a given node. Then, I normalized the regional forecast and passed it through the statistical model. The results were immediate and impressive: up to 30% better accuracy compared to the regional forecast. By leveraging the regional forecast for a given node, I was able to reframe the problem as statistical instead of predictive. This saved us months of work in development, and real money in monthly compute costs. The model could be deployed almost immediately since it requires just a couple days, not months, of training data.

Figure 1. An example where our statistical model for microclimate temperature has outperformed the regional forecast by 30%. Why is a 30% more accurate microclimate forecast important? For our customers this can mean the difference between cold and frost, or critical heat and just a really hot day, for example.
This statistical model represents about two weeks of work, from R&D to testing and deploying the updated forecast server. The model is extremely simple, easy to maintain, debug, and run. What’s more, it can run on just about any hardware, which will help us eventually leave the cloud and deliver a product that is capable of running completely offline or with minimal network connectivity.
This was a valuable lesson for our company. In a fast-paced startup environment where we pride ourselves on leveraging the latest tech to solve hard problems, we can’t overlook these simpler methods that help us save time, and ultimately ship a better product more often.